Many organizations still leverage stored procedures as their primary data transformation process. Although stored procedures can be strung together to build a data foundation, they come with multiple drawbacks, including poor auditability, scalability, and transparency. Additionally, they tend to be rigid, and updating the code in one stored procedure can cause chaos throughout the rest of the procedure process.
Stored procedures were traditionally one of the few options available to transform data effectively. However, today there are other available solutions to help data teams move beyond outdated legacy processes and take better control of their data pipelines.
One of the biggest roadblocks keeping data teams from transitioning from stored procedures to a more modern transformation approach is understanding how to convert from stored procedures to a different solution, which can seem daunting and complex at first. In this article, we’ll outline step by step how to shift from using stored procedures for data transformation to a pipeline approach, which provides more transparency and streamlined management, using Coalesce.
Downsides of using stored procedures
While stored procedures can help users tie together multiple processes within the same function, there are drawbacks to this approach.
The first drawback is that stored procedures are difficult to audit, so it can be hard to understand what’s happening within them. This makes scaling data transformations using stored procedures incredibly challenging, as managing dozens or even hundreds of stored procedures introduces a lot of complexity. When a stored procedure inevitably runs into an error, auditing and understanding the error as part of a larger data transformation process can cause frustration and lots of wasted engineering hours. It can also introduce breaking changes to other stored procedures based on the fix implemented for the current issue. Not only that, but just understanding what each step in a stored procedure is accomplishing is no trivial feat.
This leads to another core issue with stored procedures: impact analysis. Gaining the necessary visibility into up- or downstream changes, and how they impact your current data transformation process, is difficult—specifically, knowing how a change in one stored procedure is going to affect the rest of your process. Without this visibility, your data team can get bogged down with reactive, maintenance-focused work rather than devoting itself to proactive projects that move the business forward.
Finally, stored procedures tend to be brittle. Even within the same stored procedure, ensuring that each step is able to run properly and is dynamic enough to withstand changes to the broader data transformation process in the future is virtually impossible. A single column change within a source table schema can create chaos for a stored procedure, which can be difficult to identify and can impact the rest of your data transformation process.
By using a pipeline approach instead, you gain each of these issues as an advantage, as well as keep all of the logic of your stored procedures in place.
Understanding the logic of the stored procedure
Before we can begin converting stored procedures to a pipeline methodology, it’s important to understand what the code in the stored procedures is accomplishing. Understanding the logic of the stored procedure allows you to build a modular framework for how the same logic should be developed in a pipeline approach. In some cases, stored procedures may just be accomplishing a simple, linear task. In others, there may be multiple steps involved where data is processed and output in a complex manner. In each of these cases, understanding the logic of each stored procedure is critical in rebuilding the procedure process in a sustainable pipeline framework.
This is important because in a pipeline approach, each object—or node, as Coalesce calls them—represents independent SQL blocks that allow users to modularly define the logic of their pipeline. In developing pipelines this way, data teams gain multiple advantages, such as reusability, auditability, scalability, and singular point updating.
Applying this framework to stored procedures is why it’s crucial to understand the logic of each stored procedure. For each logical modular step in the stored procedure process, we would create a node for each of those steps in Coalesce.
Let’s take a look at a stored procedure, break down what’s happening in it, and how it would be rebuilt as a pipeline in Coalesce.

On line 7, we can see the first action performed by the stored procedure: the creation of a temporary table called demo_id_table. This temporary table is created with the same schema coming from the stg_location table.
Once this temporary table has been created, we can see that we alter the DDL of the table by adding a new varchar column to the table, called international_flag.
With the new flag column added, we then insert all of the data from the stg_location table into the temporary demo_id_table, where the location_ids do not exist in the dim_location_ids tables. This insertion step also contains logic for determining if the location ID is international or not, which leverages the international_flag column that was created in the previous step.
Once data is inserted into the temporary table, subsets of the table are inserted into two different dimension tables. The first subset inserts net new records into the dim_location_ids_int table, where the international_flag is filtered to “Y”. The second table, dim_location_ids_us, has net new records inserted into it where the international_flag is filtered to “N”.
Rebuilding a stored procedure in Coalesce
Now that we’ve walked through a stored procedure performing data transformation, let’s understand how to convert this to a pipeline approach in Coalesce. When migrating stored procedures into Coalesce, you do not have to rebuild from scratch (although you certainly can). Instead, you can copy the relevant code from the stored procedure directly into the platform.
The first thing we should consider is the sequential order in which the stored procedure is running each query. In most cases, this can be identified by evaluating the stored procedure in a top-down approach, with the first query being what is run first.
Once you have identified the order in which the queries in your stored procedure are running, we can begin building each step as a modular block of logic within Coalesce. For example, in the stored procedure from earlier, the processing of queries in sequential order looks like this:
- Create a temporary table
- Add a column to the temporary table
- Insert data into temporary table where records don’t exist in target tables
- Insert new records into target table 1
- Insert new records into target table 2
We can rebuild this stored procedure as a pipeline in Coalesce in this order. The first thing we will do is create the temporary table. Because this temporary table is only being used to process the data and will be unavailable at the end of the user session, or after 24 hours, we will use a view in our pipeline within Coalesce. Using a view instead of a temporary table comes with multiple advantages. First, the view can be run at any point, in isolation of the rest of the pipeline if necessary. Additionally, the view won’t be physically storing any results in Snowflake, but will exist as an object that’s easy to audit and perform impact analysis on.
If we use the same table naming conventions as the stored procedure, we can add a view (gray node), which uses the same schema as the stg_location table (green node)—exactly like in our stored procedure.

The second step in our stored procedure is adding a column for the international_flag to the temp table. In our pipeline, we can add this column into the view we just created. This only needs to be done once, and will be processed this way each time moving forward.

Next, we need to actually populate this view (temp table in the stored procedure) with data. Within the stored procedure, this queries a bit of logic. The first thing happening is the international_flag logic that’s written. We can add this into our view as a column transformation by copying and pasting the logic from our stored procedure:
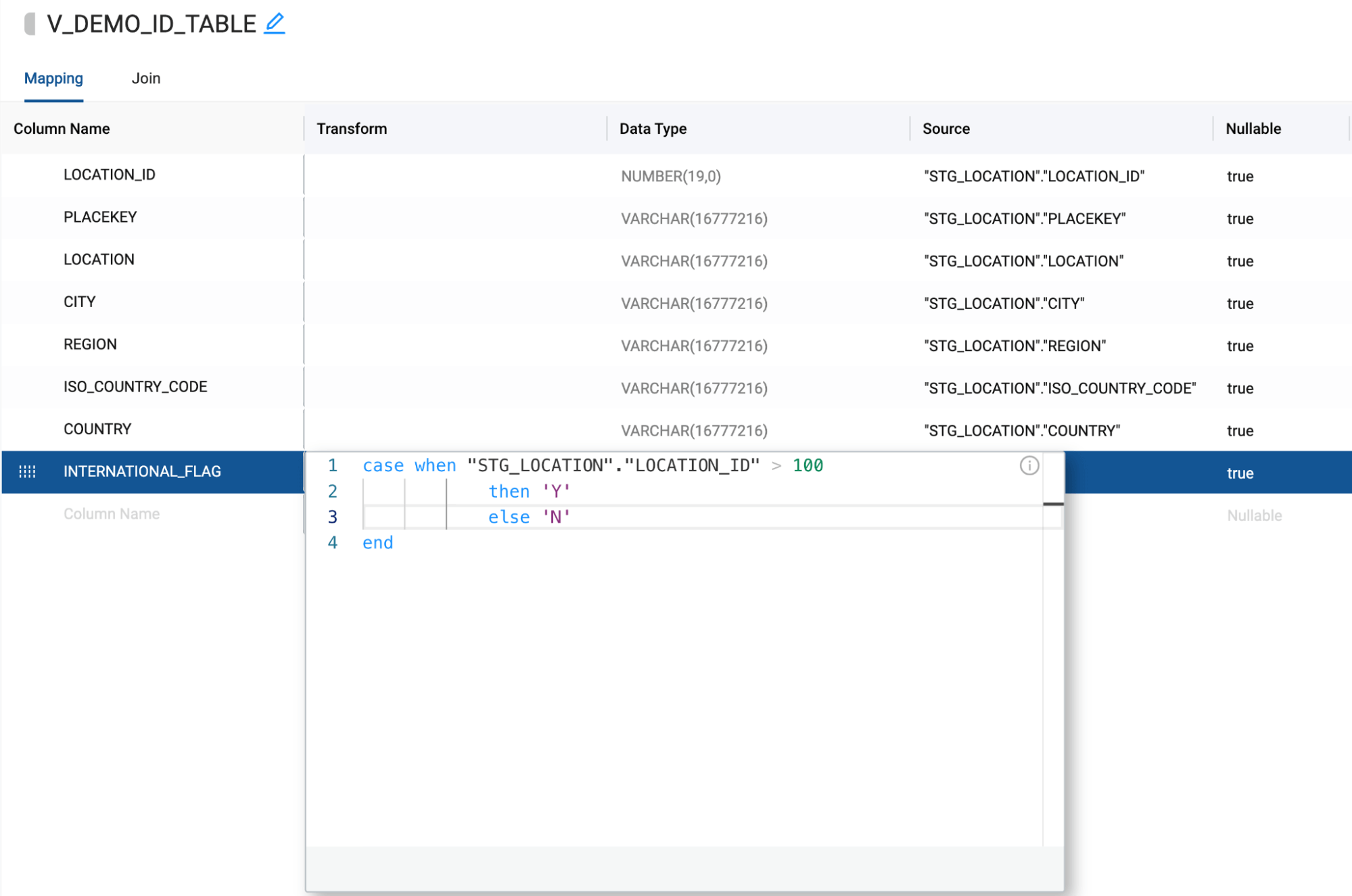
Next, we see that there’s a filter applied to this query. We can apply the same logic to our view within the Join tab of Coalesce.
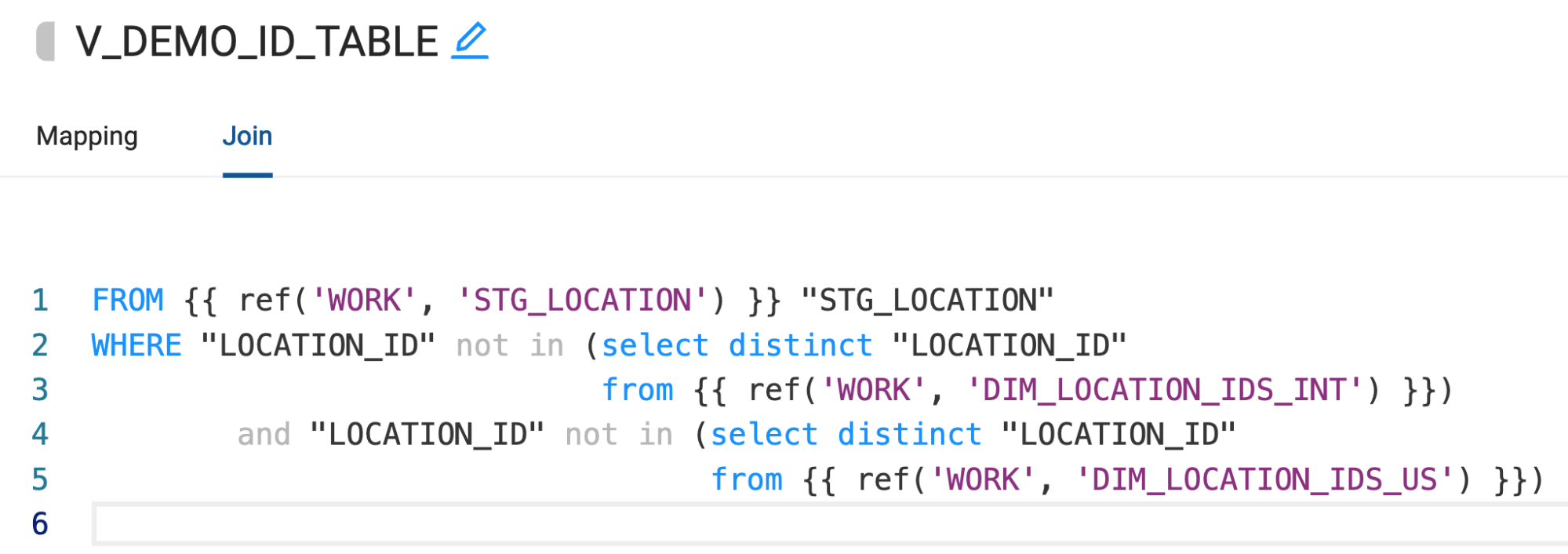
Now we’ve been able to configure the core of the logic of our stored procedure within one object in Coalesce, which is auditable, makes all the code easily accessible, contains lineage and documentation, and allows users to copy and paste the logic from the stored procedure directly into Coalesce.
Finally, we need to insert any of the net new records processed by this view into the respective dimension tables that are downstream. In this scenario, our pipeline would look like this:

In this case, we will supply a business (or unique) key to each record within the dimension nodes.

From this point on, each dimension table will capture all of the records coming from the view node we just configured. And that’s it!
Convert any stored procedure
As we’ve demonstrated, converting stored procedures to a pipeline in Coalesce is not difficult, and the long-term benefits gained far outweigh the short-term lift to migrate your code. Benefits such as column level lineage, modular model design, and simple auditability ensure users can focus more on proactive data product development and less on managing and maintaining code. Coalesce can support any type of Snowflake stored procedure functionality, often providing features and nodes that make the same process significantly easier to set up and manage.
To see Coalesce in action, take an interactive tour or contact us to request a demo.