
AI systems are only as reliable as the data that powers them. Without structured context about your data—its origin, transformations, relationships, and meaning—even the most sophisticated models produce unreliable results. This context comes from metadata, and managing it effectively has become critical infrastructure for modern data operations.
This guide covers metadata management from fundamentals through implementation: what it is, why it matters now, how to implement it, and what approaches deliver the most value. Whether you’re a data engineer building pipelines, an analyst searching for trustworthy data, or a data leader evaluating governance strategies, you’ll find actionable insights for your role.
What is metadata management?
Metadata is structured information that describes, explains, and provides context for data assets. It answers fundamental questions: Where did this data originate? How was it transformed? What does this field represent? Who can access it? What’s its quality score?
Consider a database table containing customer transaction records. The actual data includes transaction IDs, amounts, and timestamps. The metadata includes the table schema, column data types, source system information, transformation logic that created it, data quality rules applied, business definitions of each field, and access logs showing who queried it.
Common examples of metadata in practice:
- Database schemas: Table structures, column names, data types, constraints, indexes
- Transformation logic: SQL queries, mapping rules, business rules, data quality checks
- Data lineage: Source systems, ETL processes, target tables, downstream dependencies
- Business context: Definitions, ownership, stewardship, related terms, usage patterns
- Operational stats: Run times, row counts, error rates, refresh schedules, performance metrics
The four types of metadata
Effective metadata management requires handling multiple metadata types across your data ecosystem:
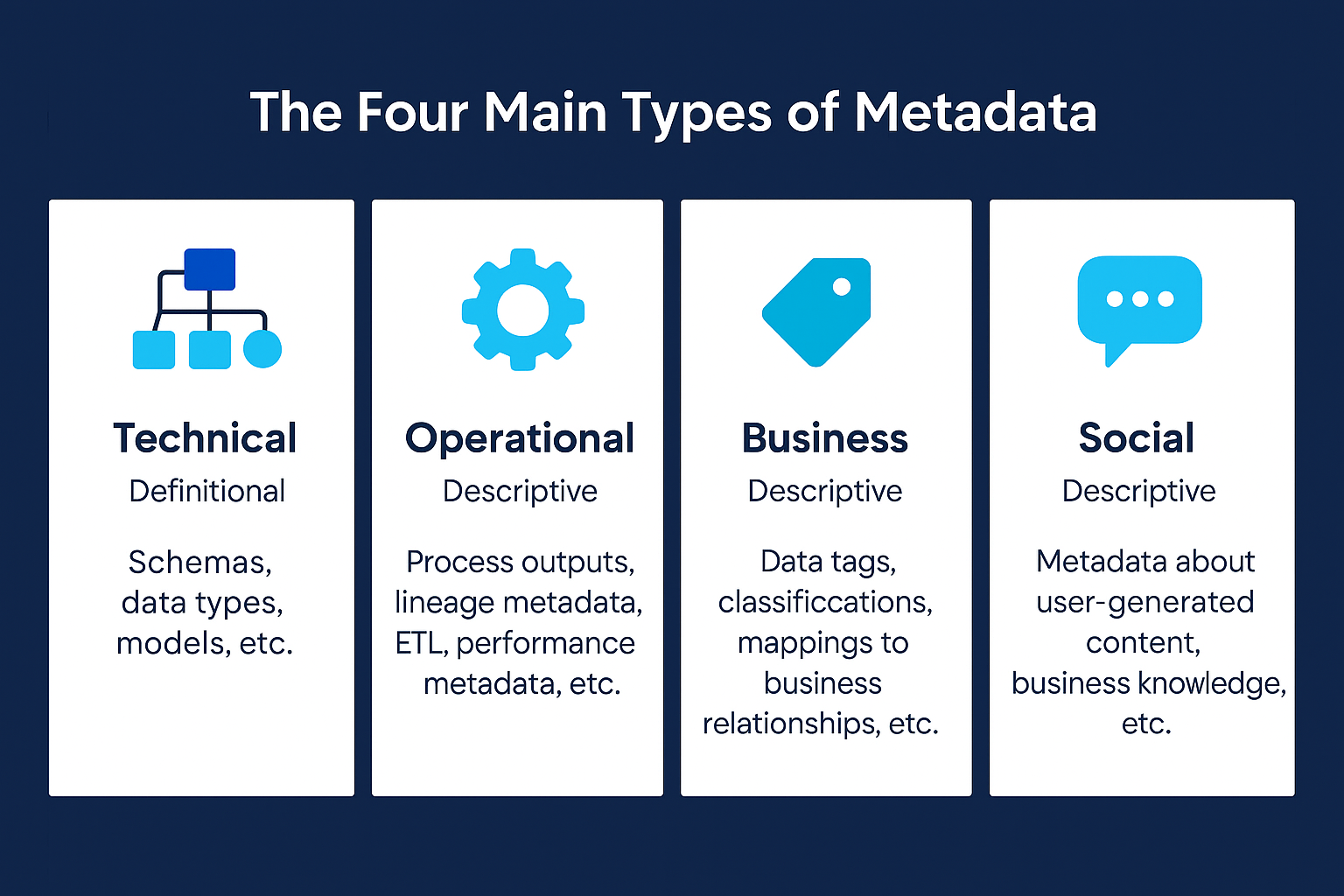
Technical metadata
Technical metadata describes the structure and format of data assets. This includes database schemas, table definitions, column names and data types, primary and foreign keys, indexes, partitioning schemes, file formats, and API specifications. Technical metadata also covers transformation logic: SQL queries, mapping documents, ETL code, data quality rules, and validation checks.
Data engineers rely on technical metadata to understand data structures, write correct transformation logic, and troubleshoot pipeline failures. Without accurate technical metadata, every pipeline change becomes risky guesswork.
Business metadata
Business metadata provides semantic meaning and context that business users understand. This includes business glossary terms, field definitions in plain language, business rules and calculations, data ownership and stewardship information, usage guidelines, and relationships to business processes.
For example, technical metadata might show a column named “cust_ltv_12m” with type DECIMAL(10,2). Business metadata explains this as “Customer Lifetime Value – 12 Month: Predicted revenue from a customer over the next 12 months, calculated using historical purchase patterns and engagement scores.”
Operational metadata
Operational metadata tracks the runtime behavior and performance of data systems. This includes job execution logs, start and end times, row counts processed, error rates and messages, system resource usage, data freshness indicators, and SLA compliance metrics.
Operations teams use this metadata to monitor data pipeline health, identify performance bottlenecks, troubleshoot failures, and ensure data availability meets business requirements.
Usage metadata (a.k.a. social metadata)
Usage metadata captures how people and systems interact with data. This includes query patterns, most frequently accessed tables, user access logs, data popularity metrics, user ratings and comments, and collaboration activity.
Usage metadata reveals which datasets matter most to your organization, identifies unused or duplicate data, helps prioritize data quality improvements, and shows knowledge gaps where better documentation is needed.
Passive vs. active metadata
Traditional metadata management treats metadata as static documentation—a reference manual that gets updated occasionally and consulted when needed. This is passive metadata.
Active metadata takes a fundamentally different approach. It continuously analyzes metadata streams from across your data ecosystem, identifies patterns and trends, generates recommendations, triggers automated actions, and feeds intelligence back into data workflows.
The difference is operational. Passive metadata documents that a table exists and what its columns mean. Active metadata knows the table hasn’t been updated in three days when it should refresh daily, identifies which downstream reports will break, recommends similar tables that are up to date, and alerts the responsible team with specific debugging context.
Active metadata makes this possible through continuous analysis, machine learning algorithms that detect anomalies and patterns, integration with workflow systems to trigger actions, and real-time updates as data moves through pipelines.
Modern metadata management platforms leverage AI to transform metadata from documentation into operational intelligence that actively improves data quality, governance, and productivity. AI-powered assistants can use metadata to understand data context, recommend relevant datasets, generate documentation, and detect anomalies.
Why metadata management matters now: The data complexity problem
Data volumes grow exponentially while simultaneously becoming more distributed and complex. Organizations manage data across cloud data warehouses, data lakes, SaaS applications, on-premises databases, streaming platforms, and external data sources. Each system has its own metadata format, governance model, and access patterns.
Without effective metadata management, this complexity creates concrete problems:
Discovery failures: Data engineers spend hours searching for the right dataset or rebuilding data that already exists elsewhere in the organization. Analysts can’t find trustworthy data to answer business questions, so they make decisions on incomplete or incorrect information.
Quality blind spots: Data quality issues propagate through pipelines undetected. By the time bad data reaches business reports, the root cause is buried in complex transformation chains. Teams lack the lineage to trace problems back to their source.
Governance gaps: Compliance teams can’t prove data provenance or demonstrate that sensitive data is properly protected. Access control is inconsistent across systems. When regulators ask “Where did this number come from?” the answer requires weeks of manual investigation.
Integration gridlock: Every new data source requires custom integration work. Teams can’t reuse existing patterns or understand how new data relates to current assets. Integration projects take months instead of weeks.
The cost of these problems compounds. Gartner estimates that poor data quality costs organizations an average of $12.9 million annually. The hidden costs—missed opportunities, delayed decisions, compliance risk—are higher still.
Critical business drivers
AI & machine learning enablement
Large language models and AI systems require structured context to produce reliable results. An LLM without metadata context might confidently tell you that Q4 revenue increased 40% when it actually declined, because it misinterpreted a percentage_change column or confused revenue with profit margin.
Metadata provides the context AI needs:
- Data definitions explain what fields mean and how they’re calculated
- Lineage shows how training data was derived and what transformations were applied
- Quality metrics help models weight different data sources appropriately
- Relationships reveal connections between entities that improve prediction accuracy
- Business rules ensure AI-generated insights align with organizational standards
Without robust metadata, AI & AI data engineering initiatives face higher error rates, unexplainable predictions, difficulty reproducing results, and compliance risks when models can’t prove how they reached conclusions.
Data governance & compliance
Regulatory requirements around data privacy, security, and lineage intensify across industries. GDPR, CCPA, HIPAA, and sector-specific regulations require organizations to demonstrate data provenance, enforce access controls, maintain audit trails, and respond to data subject requests.
Metadata management provides the foundation for effective governance. It documents what sensitive data exists and where it’s stored, tracks who accessed what data and when, maintains lineage from source through transformation to consumption, enables automated policy enforcement, and provides audit trails for compliance reporting.
Without comprehensive metadata, governance becomes manual, inconsistent, and error-prone. Organizations face compliance violations, data breaches from inadequate access control, and inability to respond to regulatory inquiries.
Operational efficiency
Data teams waste significant time on low-value activities that metadata management eliminates. Engineers spend hours searching for existing datasets, reverse-engineering undocumented transformations, and debugging pipeline failures. Analysts repeatedly ask the same questions about data definitions and trustworthiness. Multiple teams build duplicate pipelines because they can’t discover existing work.
Effective metadata management recovers this lost productivity by making data discoverable through comprehensive catalogs, eliminating guesswork with clear documentation and lineage, accelerating development with reusable patterns and templates, reducing debugging time through automated impact analysis, and preventing duplicate work through visibility into existing assets.
Organizations that implement metadata management report dramatic improvements in data team productivity. Engineers build pipelines faster, analysts spend more time on analysis instead of data hunting, and data quality issues are detected and resolved earlier.
Core capabilities of metadata management
Metadata capture and integration
Effective metadata management begins with comprehensive, automated metadata capture from across your data ecosystem. Manual metadata documentation fails because it requires constant upkeep, quickly becomes outdated, covers only a fraction of your data estate, and creates maintenance burden that teams can’t sustain.
Modern metadata management platforms automate capture through direct integration with data sources, APIs that extract metadata from databases, data warehouses, and SaaS platforms, code parsing that analyzes SQL, Python, and transformation logic to extract lineage and business rules, monitoring agents that collect operational metadata from pipeline executions, and user activity tracking that captures usage patterns and popularity.
![]()
The breadth of integration matters. Metadata scattered across disconnected systems provides limited value. Comprehensive metadata management requires connecting sources including cloud data warehouses, data lakes and object storage, operational databases, SaaS applications, BI and analytics tools, ETL and data integration platforms, and data science and ML platforms.
Automated capture ensures metadata stays current as systems change, provides comprehensive coverage across your data estate, reduces manual maintenance burden, and captures metadata that would never be documented manually.
Data lineage
Data lineage traces data flows from origin through transformation to consumption. It answers critical questions: Where did this data come from? What transformations were applied? What downstream assets will break if I change this table? How was this metric calculated?
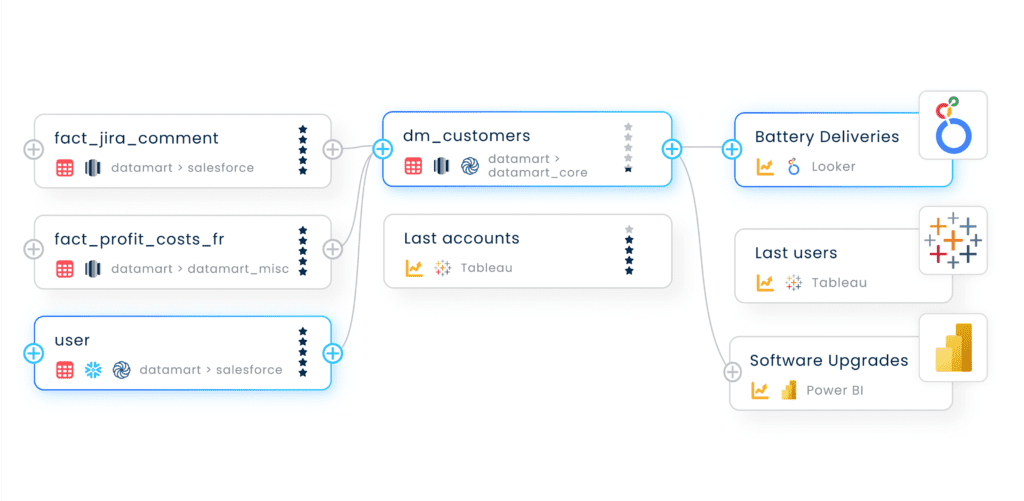
Lineage operates at multiple levels of granularity. Table-level lineage shows relationships between tables and datasets. Column-level lineage traces individual fields through transformations. Business lineage connects technical lineage to business processes and reporting.
The most valuable lineage is automated and derived from actual code execution rather than manually documented. Automated lineage is always current, complete across your entire data estate, and includes detailed transformation logic.
Lineage enables critical use cases including impact analysis before making changes, root cause analysis when data quality fails, regulatory compliance by proving data provenance, development acceleration through understanding existing patterns, and data migration by mapping legacy to modern systems.
Without comprehensive lineage, teams operate blind. Every change is risky, debugging takes days instead of minutes, and compliance requirements become manual investigations.
Data cataloging and discovery
Data catalogs provide searchable inventories of data assets across your organization. They make data discoverable, understandable, and accessible to users who need it.
Effective catalogs go beyond simple search with intelligent search that understands business terms and technical names, recommendations that suggest relevant datasets based on usage patterns and similarity, rich context including definitions, lineage, quality scores, and usage statistics, user collaboration through ratings, reviews, and questions, and governance indicators showing certification status, sensitivity, and access requirements.

The catalog serves different personas. Data engineers need technical metadata to understand schemas and dependencies. Analysts need business context to know if data is trustworthy and appropriate for their use case. Data stewards need governance metadata to manage policies and access.
Modern catalogs leverage AI to enhance discovery with automated classification that tags data with business terms and sensitivity labels, semantic search that finds relevant datasets even when exact terms don’t match, data profiling that analyzes content to suggest descriptions and quality issues, and automated documentation that generates human-readable descriptions from technical metadata.
Learn more: Explore Coalesce Catalog or read our guide to the top 10 data catalog tools in 2025.
Data quality management
Metadata management provides the foundation for comprehensive data quality programs. It makes quality issues visible, traceable, and preventable.
Key quality capabilities built on metadata include data profiling that automatically measures quality dimensions like completeness, accuracy, consistency, timeliness, and uniqueness. Quality scoring summarizes overall data quality in simple metrics. Quality rules define expected characteristics that data should meet. Automated validation checks data against rules and alerts when violations occur. Lineage-based root cause analysis traces quality failures to their source.
Metadata enables proactive quality management. Impact analysis shows what breaks before deploying changes. Templates encode quality best practices that get applied automatically. Feedback loops capture user reports of quality issues and guide improvement priorities.
The result is quality that improves continuously. Issues are detected earlier, fixed faster, and prevented from recurring. Data consumers gain confidence in data trustworthiness.
Governance and compliance
Metadata management transforms governance from manual processes to automated policy enforcement. It provides the data inventory, lineage, and access tracking that compliance requires.
Governance capabilities enabled by metadata include policy management that defines data handling rules, classifications, and access requirements. Automated classification tags sensitive data based on content and context. Access control enforcement ensures users can only access appropriate data. Audit trails capture who accessed what data and when. Compliance reporting provides evidence for regulatory requirements.
Effective governance is distributed, not centralized. Metadata management enables federated governance with domain ownership where business units govern their own data, centralized policy definition with local enforcement, automated compliance checks rather than manual reviews, and self-service access within governed boundaries.
The balance between enablement and control is critical. Overly restrictive governance slows teams and drives shadow IT. Metadata-driven governance provides guardrails that maintain compliance while enabling self-service data access.
Metadata management implementation strategies
Start with clear objectives
Metadata management initiatives fail when they lack clear business objectives. “Better data governance” is too vague. Successful implementations target specific, measurable outcomes.
Common objectives that drive metadata management include reducing compliance risk by proving data lineage and access controls, accelerating development by eliminating search time and enabling pattern reuse, improving data quality through automated detection and root cause analysis, enabling AI initiatives through comprehensive data context, and reducing operational costs by consolidating tool sprawl.
Choose objectives based on your most acute pain points. If regulatory risk is your primary concern, prioritize lineage and audit capabilities. If development velocity is the issue, focus on cataloging and reusable patterns. If data quality plagues your organization, emphasize profiling and quality rules.
Clear objectives drive implementation prioritization, technology selection, success metrics, and stakeholder buy-in. They keep initiatives focused on delivering measurable business value.
Choose the right scope
Metadata management can’t be implemented everywhere simultaneously. Trying to boil the ocean guarantees failure. Successful implementations start focused and expand systematically.
Begin with high-value domains. Identify critical data assets that support key business processes, have significant quality issues, face compliance requirements, or feed AI and analytics. Implement metadata management there first.
A phased approach might prioritize customer data for GDPR compliance, financial data for audit requirements, product analytics for decision support, or data science platforms for AI governance.
Starting focused provides several advantages including faster time to value with concrete wins, focused investment without overwhelming budgets, learning and refinement before broader rollout, and stakeholder confidence from visible success.
After proving value in initial domains, expand systematically. Let success drive adoption. Teams that see value will demand metadata management for their domains.
Automate or fail
Manual metadata documentation fails. Every organization that tries it reaches the same conclusion: the documentation is always incomplete, quickly becomes outdated, can’t keep pace with change, and requires unsustainable effort.
Successful metadata management is built on automation. Metadata is captured automatically from code, systems, and operations. It stays current through continuous refresh. It’s enriched through AI that classifies, profiles, and generates descriptions.
The automation principle extends beyond capture. Governance policies are enforced automatically through code. Quality checks run automatically on data pipelines. Lineage updates automatically when code changes. Anomalies trigger automatic alerts.
This doesn’t eliminate human judgment. People define policies, curate definitions, and respond to issues. But automation handles the repetitive work that humans inevitably fail to sustain.
When evaluating metadata management platforms, automation breadth is the critical differentiator. How much metadata is captured automatically? How current does it stay? How much manual maintenance does it require?
Design for distributed ownership
Centralized metadata management doesn’t scale. A central team can’t possibly catalog all data, document all definitions, and govern all access across an enterprise.
Successful implementations distribute ownership. Domain teams own metadata for their data. They define business terms, document transformations, and govern access. A central team provides standards, tools, and guidance, but doesn’t become a bottleneck for every metadata decision.
Distributed ownership requires clear boundaries and responsibilities. Each domain owns specific data assets. They’re accountable for metadata quality, documentation completeness, and governance compliance. Central teams define enterprise standards but don’t control local decisions.
Technology must support distributed ownership. Domain teams need self-service tools to manage their metadata. Governance policies apply automatically without central approval for every change. Cross-domain search and lineage work seamlessly despite distributed control.
This federated model balances autonomy and consistency. Domains move quickly within their boundaries. Enterprise standards ensure interoperability and compliance.
Integrate with existing workflows
Metadata management fails when it’s a separate tool that requires context switching. Engineers won’t leave their IDE to document metadata in another system. Analysts won’t check a catalog if it’s not integrated with their BI tool.
Successful implementations embed metadata in existing workflows. For data engineers, metadata capture is integrated with pipeline development. Writing transformation code automatically captures lineage. Templates include metadata and governance rules by default. Quality checks are part of the development process, not a separate step.
For analysts, metadata appears in their familiar tools. BI platforms show data definitions and quality scores inline. Query tools suggest datasets based on usage patterns. Governance restrictions are enforced transparently.
For data stewards, governance happens where data is used, not in separate systems. Policy violations trigger alerts in operational tools. Access requests are handled through existing workflows.
The best metadata management is invisible. Users gain the benefits without changing how they work.
Measuring success
Metadata management initiatives require clear success metrics. Track outcomes that matter to your organization.
Efficiency metrics
Measure how metadata management reduces wasted effort. Track time to find data and understand it, development cycle time for new pipelines, debugging time when issues occur, and duplicate work eliminated through discovery.
McKinsey reports that organizations typically see a 40-60% reduction in time spent searching for and understanding data, 30-50% faster development of new pipelines, and 50-70% faster resolution of data quality issues.
Quality metrics
Track improvements in data quality. Measure data quality scores across dimensions, number of quality issues detected, time to resolution, and downstream impact prevented.
The goal isn’t just finding more issues. It’s catching them earlier, fixing them faster, and preventing recurrence.
Governance metrics
For compliance-driven initiatives, track policy coverage, audit readiness, time to respond to regulatory requests, and access control consistency.
Success means demonstrating compliance without manual investigation, responding to audit requests in hours instead of weeks, and eliminating compliance violations from inadequate governance.
Adoption metrics
Track user engagement with metadata. Measure catalog usage and search activity, metadata quality and completeness, user contributions and collaboration, and satisfaction scores from surveys.
Low adoption indicates poor user experience or insufficient value. High adoption with poor outcomes suggests the wrong capabilities or implementation approach.
Common challenges and solutions
Challenge: Metadata quality and completeness
Automated capture provides technical metadata, but business context requires human input. How do you ensure metadata is complete and maintained?
Solution: Distribute ownership to domain experts. They understand the business context and have incentive to document their data. Make contribution easy through in-context editing and AI-assisted generation. Track completeness metrics and gamify contributions. Most importantly, demonstrate value so users want comprehensive metadata.
Challenge: Cross-platform lineage
Data flows through multiple systems. How do you trace lineage across platform boundaries?
Solution: Use platforms that integrate broadly or invest in connectors for key systems. Focus on complete coverage of your most critical data flows rather than partial coverage everywhere. Consider unified platforms that handle transformation and cataloging together, eliminating integration challenges.
Challenge: Scale and performance
Metadata grows as fast as data. How do you keep metadata systems performant?
Solution: Use platforms built for scale with distributed architecture. Prioritize incremental updates over full scans. Index strategically for common queries. Archive historical metadata that’s rarely accessed.
Challenge: Balancing governance and agility
How do you enforce governance without slowing teams?
Solution: Automate policy enforcement so governance happens transparently. Provide self-service access within governed boundaries. Use metadata to enable rather than restrict. The right balance makes compliant paths the easy paths.
Challenge: Justifying investment
How do you build the business case for metadata management?
Solution: Quantify current costs of poor metadata. Calculate time wasted searching, rework from quality issues, and compliance risk. Compare to efficiency gains from metadata management. Start with high-value use cases that deliver quick wins.
The future of metadata management
Metadata management is evolving rapidly. Several trends are reshaping the landscape.
AI-powered metadata
AI transforms metadata from documentation to intelligence. Machine learning analyzes metadata to classify data automatically, detect quality anomalies, recommend relevant datasets, generate natural language descriptions, and predict data usage patterns.
AI-powered assistants use metadata to answer natural language questions about data, suggest optimal datasets for analysis, generate transformation code, and explain data lineage in business terms.
The feedback loop accelerates. AI generates metadata, which improves AI results, which generates better metadata.
Active metadata everywhere
The shift from passive to active metadata continues. Metadata becomes operational infrastructure that drives automation, not just documentation that humans consult.
Active metadata enables self-healing data pipelines that detect and correct issues automatically, intelligent data products that adapt based on usage, predictive data quality that prevents issues before they occur, and automated governance that enforces policies without human intervention.
Convergence with data platforms
Standalone metadata tools are giving way to unified platforms where metadata is embedded throughout data operations. Instead of separate cataloging tools, metadata capabilities are built into data transformation, pipeline development, and governance platforms.
This convergence eliminates integration challenges, keeps metadata current automatically, and provides seamless experiences across development, discovery, and governance.
Federated and decentralized governance
Metadata management enables true data mesh architectures with domain-oriented data ownership. Domains control their data and metadata while participating in federated governance. Metadata provides the interoperability that makes decentralization viable.
This aligns with organizational trends toward distributed ownership and product thinking about data.
Getting started
Metadata management is foundational infrastructure for modern data operations. It transforms data from opaque assets into understandable, governable, trustworthy resources that power analytics and AI.
The path forward:
- Assess your current state: Where is metadata scattered? What pain points exist? What business value would better metadata deliver?
- Define clear objectives: Solve specific problems—reduce compliance risk, accelerate development, improve data quality, enable AI—rather than vague “better data governance.”
- Start focused: Choose high-value domains and use cases for initial implementation. Prove value, then expand.
- Automate from the start: Manual metadata documentation fails. Build on platforms that automate capture, keep metadata current, and use metadata operationally.
- Design for scale: Implement distributed ownership, governance automation, and technical architecture that handles growth.
The shift from passive documentation to active, operational metadata is transformative. Organizations that make this shift report dramatic improvements in development velocity, data quality, governance effectiveness, and AI readiness.
Next steps with Coalesce
Coalesce takes a unified, metadata-first approach to data transformation and governance. Metadata is embedded throughout the platform, captured automatically as you build pipelines, and used to drive development, discovery, and governance.
See how it works:
- See a Demo – Watch how Coalesce captures column-level lineage automatically, generates transformation code from metadata templates, and unifies catalog, governance, and transformation in one platform.
- Take an Interactive Product Tour – Explore the platform yourself. See how engineers build data pipelines, analysts discover data with full context, and stewards govern data—all in one unified experience.
The future of data operations is metadata-driven. Organizations that embrace comprehensive metadata management now will build competitive advantages in data quality, AI readiness, and operational efficiency.
Frequently Asked Questions About Metadata Management
Metadata management is the systematic process of creating, storing, organizing, and maintaining metadata across an organization’s data assets. It ensures data is discoverable, understandable, trustworthy, and governable throughout its lifecycle.
Effective metadata management combines automated capture from diverse sources, comprehensive cataloging and search, detailed lineage tracking, data quality monitoring, governance and compliance capabilities, and collaboration features for distributed ownership.
The goal is transforming data from opaque assets into well-understood, trustworthy resources that power reliable analytics and AI.
Passive metadata is static documentation that describes data assets. It’s like a reference manual that gets consulted when needed but doesn’t actively participate in data operations.
Active metadata continuously analyzes metadata streams to identify patterns, detect anomalies, generate recommendations, and trigger automated actions. It’s dynamic and operational.
Active metadata is like a smart assistant. It monitors data systems, notices when patterns deviate, alerts you to problems, recommends solutions, and can even take automated corrective actions.
Key differences:
- Update frequency: Passive updates periodically (batch scans). Active updates continuously (real-time streams).
- Intelligence: Passive requires users to query and interpret. Active analyzes proactively using ML to surface insights.
- Action: Passive documents. Active drives automation and triggers workflows.
- Integration: Passive is often separate from data operations. Active is deeply integrated with data pipelines and workflows.
Modern platforms use active metadata to power intelligent features like automated data quality recommendations, anomaly alerts and root cause analysis, impact prediction before changes, intelligent dataset recommendations, and automated policy enforcement.
Metadata management addresses root causes of poor data quality.
Visibility into quality issues: Metadata profiling automatically measures data quality dimensions like completeness, uniqueness, validity, consistency, and timeliness. Quality scores make issues visible immediately rather than discovering them when reports break.
Lineage for root cause analysis: When data quality fails, lineage traces the problem back to its source. Instead of manually investigating, engineers follow lineage upstream to the transformation or source system that introduced bad data. This reduces debugging time from days to minutes.
Impact analysis prevents issues: Before deploying changes, impact analysis shows what breaks. This prevents deploying schema changes that violate downstream assumptions, transformation logic that produces invalid values, and breaking changes to data contracts.
Automated quality rules: Metadata defines expected data characteristics—value ranges, formats, referential integrity, freshness requirements. Systems automatically validate data against these rules and alert when violations occur. This catches issues before they propagate downstream.
Standardization through templates: Templates encode data quality best practices. When engineers use templates to generate pipelines, quality checks are included automatically. This ensures consistent quality approaches across the organization.
Quality feedback loops: Usage metadata shows which datasets have quality problems (low ratings, quality issue reports). This feedback guides improvement priorities. Fix the data quality issues that actually impact users.
Metadata management tools fall into several categories:
Data catalogs: Focused primarily on discovery and search. They extract metadata from various sources, provide searchable inventories, maintain business glossaries, and show basic lineage. Explore our guide to the top 10 data catalog tools in 2025 >
Metadata management platforms: Comprehensive platforms handling full metadata lifecycle including automated capture and integration, advanced lineage tracking, governance workflows, data quality management, and collaboration features.
Unified data platforms: Modern platforms like Coalesce embed metadata throughout data operations. Instead of separate catalog tools, metadata is integral to data transformation, pipeline development, and governance. Metadata is captured automatically as code is written and stays current as systems change.
Key capabilities to evaluate:
- Automation: How much metadata capture is automated vs. manual?
- Lineage granularity: Table-level or column-level? Automated from code or manually documented?
- Integration breadth: Does it connect to your data sources and consumption tools?
- User experience: Can all personas use it effectively?
- Governance features: Policy enforcement, workflows, audit trails, compliance reporting
- AI capabilities: Automated classification, recommendations, anomaly detection
- Architecture: Separate tool or unified with transformation platform?
The right choice depends on your specific needs—discovery focus vs. operational needs, breadth of data sources, user personas, governance requirements, and existing tool landscape.