Key Takeaways
To build an effective data team, start by assessing your data maturity and laying foundations in strategy, governance, and analytics. Begin lean with versatile talent, automate wherever possible, and choose a team structure (centralized, embedded, or federated) that fits your stage of growth.
- Start with maturity, not hype. Stabilize descriptive/operational analytics and a governed metrics layer before chasing ML.
- Hire for capabilities, then sequence. Begin with an Analytics Engineer and Data Engineer; add Platform/Governance and Quality/Reliability as scale and risk grow; embed analysts when domain demand spikes.
- Choose structure by stage. Centralized early for standards, embedded for domain speed, then a federated CoE for scale—shared platform, contracts, lineage, and domain pods.
- Automate first. Offload ingestion, testing, docs, and lineage so the team focuses on value; hire only when automation can’t cover the gap and ROI is clear.
- Prevent metric drift. Use data product contracts (schemas, SLAs, owners) and column-level lineage to keep definitions consistent and incidents down.
Building a modern data team is less about titles and more about sequencing the right capabilities and strategies at the right time. Start by grounding your organization’s data maturity—make descriptive and operational analytics reliable, standardize definitions in a metrics layer, and automate the busywork.
From there, hire deliberately and choose a structure that fits your stage: centralized for consistency, embedded for domain speed, and a federated Center of Excellence when multiple domains need both autonomy and shared standards.
The roadmap below shows how to staff, structure, and scale without trading off governance or velocity.
First, understand your data maturity
Before you begin building your team, assess your company’s data maturity. Maturity doesn’t correlate with company size. Even large organizations can lack basic visibility into their data. Instead, consider how well you understand the past, monitor the present, and forecast the future using data.
For example, can you clearly identify:
- What drove revenue growth last quarter?
- What core KPIs are consistently needed across teams within trusted dashboards?
- What drives churn or customer lifetime value using historical data?
These questions map to three analytics layers: descriptive (understanding the past), operational (tracking the present), and predictive (forecasting the future).
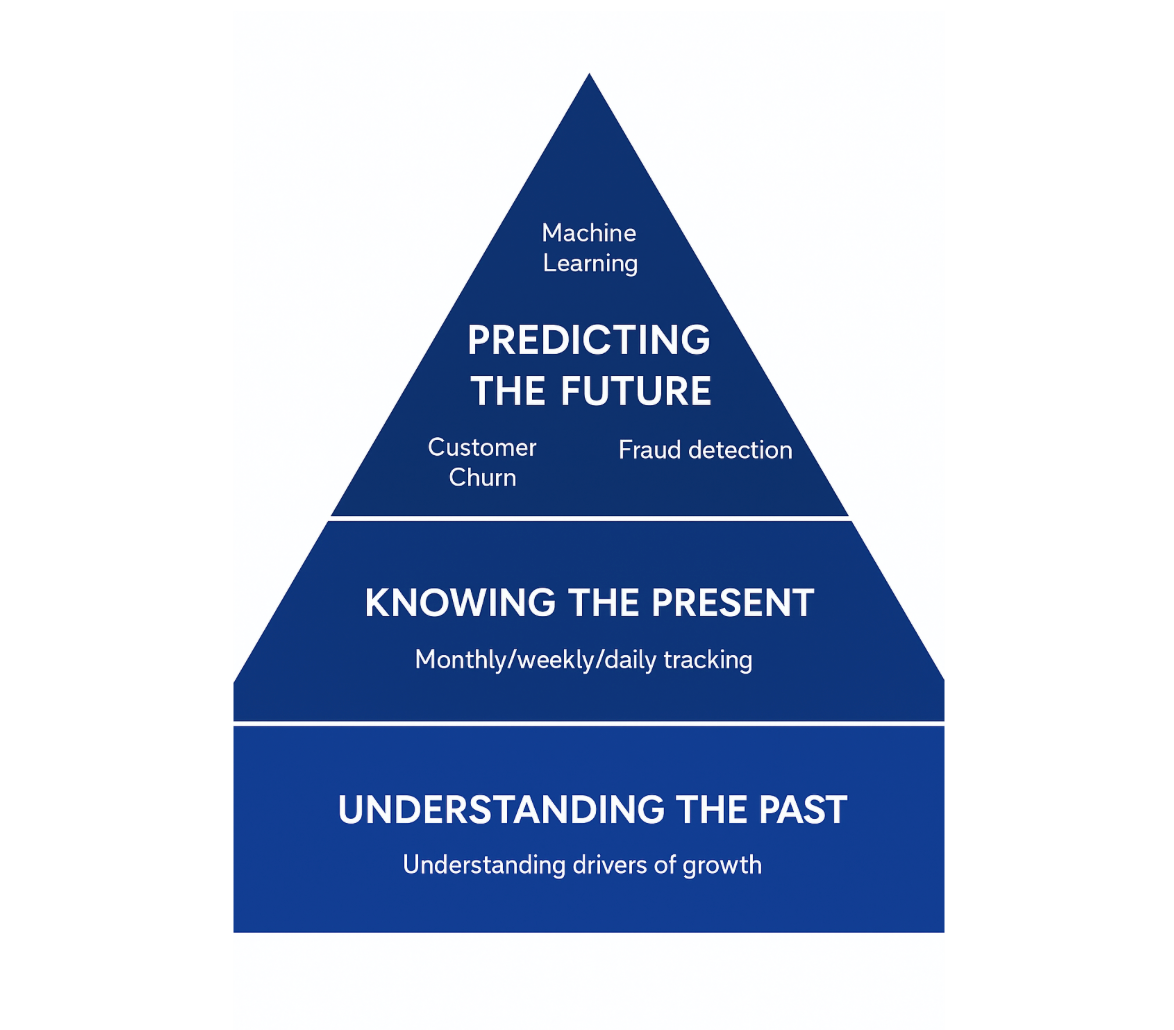
If your team is still struggling to understand what happened last month or quarter, don’t rush into building advanced models. Start by focusing on a sustainable data foundation that you can trust for accurate reporting.
What roles do I need on my data team?
Successful data teams bring together people with different strengths—some more technical, some more analytical—to support their data strategy and business goals. This can include data engineers, architects, scientists, analysts, and more. What matters most is creating the right environment: providing the resources, shared definitions, and modern tooling that enable each team member to contribute effectively and grow with the organization.
Below are some of the most common data team roles and responsibilities to consider as you build out your data team and strategy.
Head of Data / CDAO
- Owns data strategy, operating model, and value realization.
- KPIs: business impact (e.g., churn ↓, LTV ↑), time-to-insight, adoption.
- Hire when: data spend and stakeholders are growing faster than outcomes.
Data Platform Lead / Architect
- Designs the platform (warehouse/lakehouse, pipelines, orchestration, catalogs).
- KPIs: platform reliability (SLAs), cost per query/model, reusability.
- Hire when: ingestion and transformation sprawl is slowing delivery.
Data Engineer
- Builds/maintains pipelines; optimizes performance and cost.
- KPIs: pipeline SLAs, freshness, failure rate/MTTR.
- Hire when: analysts are babysitting pipelines or freshness is slipping.
Analytics Engineer
- Models data for analysts; owns testing, documentation, semantic layers.
- KPIs: model test coverage, downstream incident rate, BI adoption.
- Hire when: ad-hoc SQL is duplicative and metrics definitions diverge.
BI / Data Analyst
- Explores data, builds dashboards, communicates insights.
- KPIs: decision velocity, dashboard adoption, stakeholder NPS.
- Hire when: teams can’t self-serve or keep re-asking the same questions.
Data Product Manager
- Treats datasets/metrics as products; owns contracts, SLAs, and roadmap.
- KPIs: on-time delivery vs roadmap, usage of data products, issue backlog.
- Hire when: you move to a productized model (mesh/federated).
Data Governance Lead / Steward
- Defines policies, ownership, glossary; drives compliance and lineage.
- KPIs: policy coverage, PII exposure incidents, definition completeness.
- Hire when: multiple domains/BI tools disagree on the “same” metric.
Data Quality / Reliability Engineer (DQ/DRE)
- Builds tests, monitors quality, responds to data incidents.
- KPIs: incidents per month, mean time to detect/repair, test flakiness.
- Hire when: broken dashboards and flaky models are common.
Data Scientist / ML Engineer (as needed)
- Experiments, models, productionizes ML.
- KPIs: model lift, time to deploy, model reliability and drift.
- Hire when: predictive use cases have clear ROI and clean data.
Pro tip: one person can wear multiple hats early on. Don’t chase titles—cover capabilities.
How big should the data team be?
There’s no single formula for the perfect team size—it depends on your company’s maturity, priorities, and tooling. What matters more are a few guiding principles:
- Your org should never rely on one person knowing everything—knowledge and ownership need to be distributed.
- With the right tools, a small team can support a large organization.
- Automate as much as possible so the team focuses on meaningful, value-added work.
- Only hire when automation can’t cover the gap, and when there’s true strategic value to be gained.
For many companies, this means starting lean—often just a couple of people who can cover both infrastructure and analysis. As needs grow, add based on skill gaps rather than chasing specific titles. The collective skill set—SQL, modeling, business communication, visualization—is what drives success, not finding a “unicorn” hire.
Ultimately, a healthy data team balances operational support (“run”) with long-term initiatives (“build”). If all energy goes into ad hoc requests, it’s a sign that scaling—through better tooling, automation, or selective hiring—may be overdue.
How do I choose the right data team structure?
There’s no single correct way to structure a data team—but there are three common models that fit different stages of maturity: centralized, embedded (decentralized), and federated (hybrid).
Centralized data team structure
In a centralized model, all data professionals sit in a core team. This team typically owns the data platform and services requests from across the business. It’s an ideal setup for early-stage teams because it allows for standardization and governance.
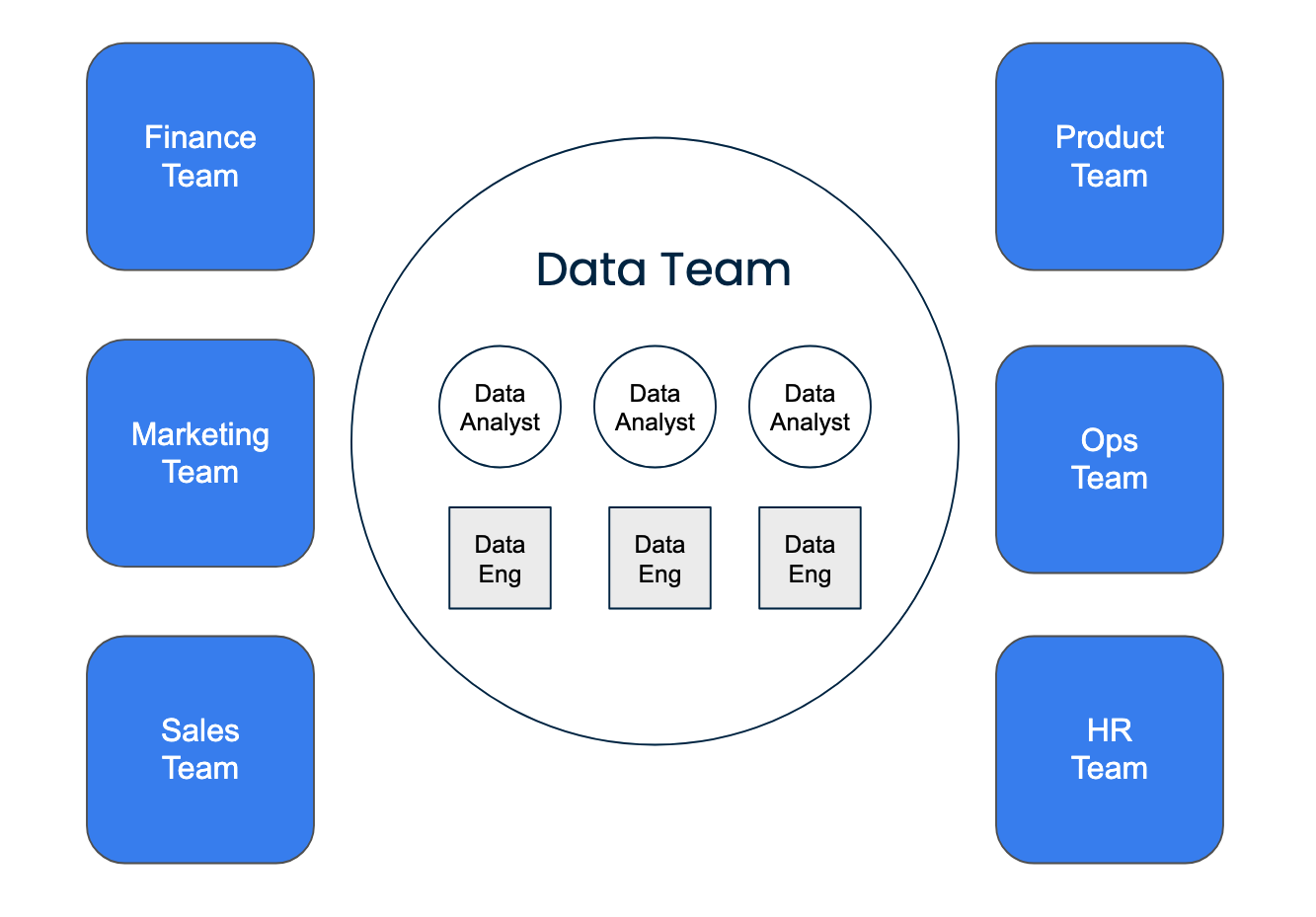
The drawback, however, is potential misalignment with business units. Analysts may not fully understand the context of the requests they’re addressing, and teams can feel like data operates as a support desk.
Decentralized data team structure
In a decentralizer or embedded model, analysts and data scientists sit directly within business functions—such as product, finance, or marketing—where they report to functional leaders and focus on department-specific needs. The upside is speed and domain expertise, as these analysts are close to the problems they’re solving.
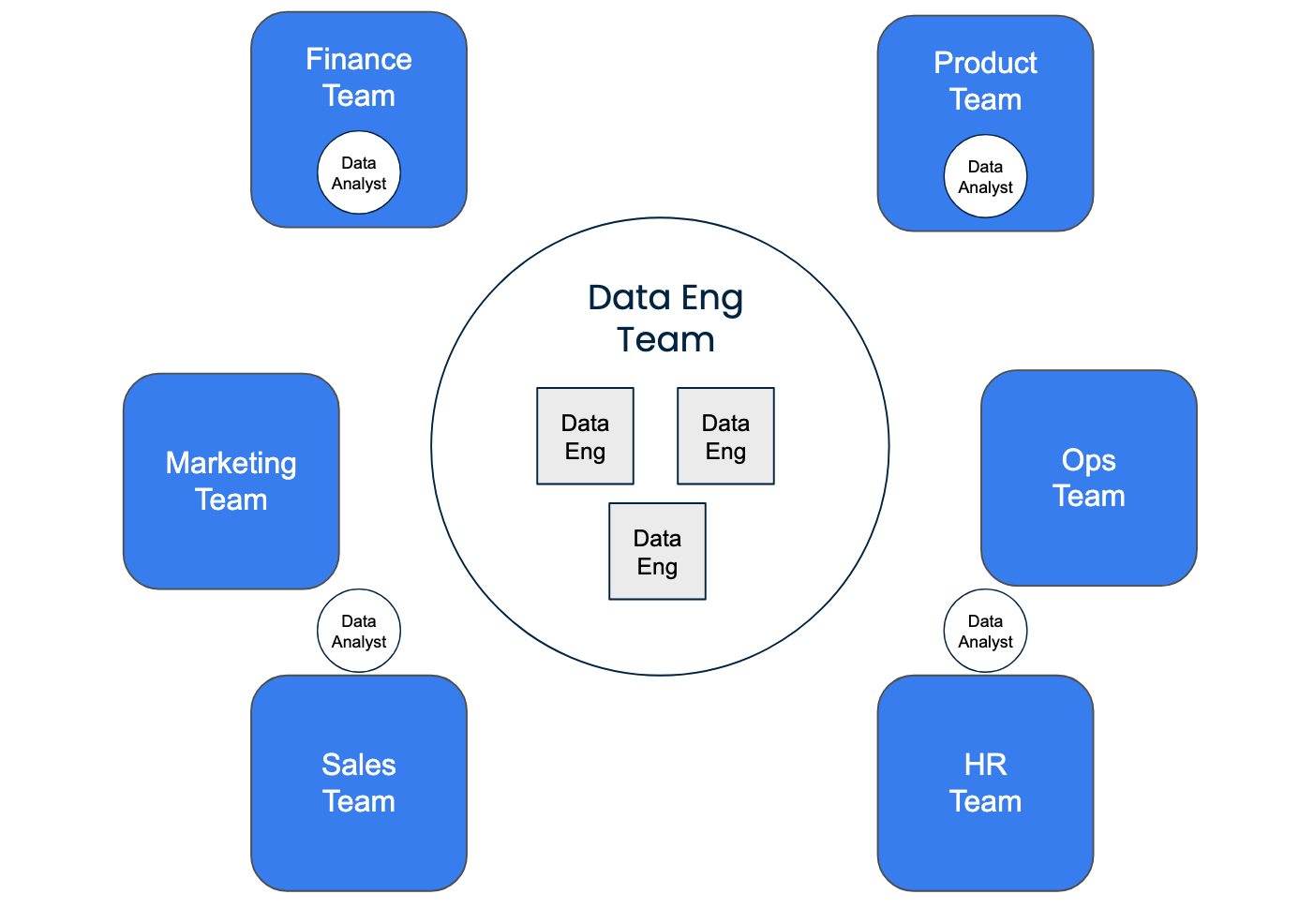
The challenge, however, is that without a unifying framework you risk duplicating efforts, creating conflicting definitions, and losing governance. This is where concepts like Data Mesh come in: giving individual domains ownership and autonomy while still enforcing shared standards for quality, governance, and interoperability across the organization.
Hybrid data team structure
In a federated structure, sometimes called a hybrid or Center of Excellence (CoE), you blend both models. A central data team provides shared standards, tooling, and training, while analysts remain embedded within departments. This model is typically adopted by more mature organizations that want both agility and alignment. It works best when there’s strong communication between business units and the CoE, and when governance is enforced centrally.
Data team model comparison: Strengths and trade-offs
| Model | Best For | Strengths | Trade-Offs |
|---|---|---|---|
| Centralized | Early stage; need standardization and governance | Consistent tooling/definitions; easier quality + security | Can become a ticket queue; weaker domain context |
| Embedded / Decentralized | Fast-moving domains; strong local context | Speed; deep domain knowledge; fewer handoffs | Duplicated work; conflicting metrics; tool sprawl |
| Hybrid / Federated (CoE) | Scaling orgs; multiple domains | Shared platform + standards; local agility | Requires clear contracts, training, and strong CoE rituals |
How should I scale my data team?
There’s no perfect blueprint for building a data team—but there are principles that can guide your approach. Understand where you are in your data journey before hiring. Start by providing value to the organization. Build for flexibility. Structure your team based on the problems you need to solve today, while leaving room to evolve.
Whether you adopt a centralized, embedded, or federated model, the goal remains the same: empower people to make better decisions with data. The faster your team can turn raw inputs into trusted insights, the more competitive your business will be.
Start with the essentials—modeling and ingestion—then add platform, governance, and reliability as scale and risk increase. As domain needs expand, embed analysts; when multiple domains are shipping independently, formalize a federated CoE with shared standards and automation.
Stage 0–1: Foundation (0–3 people)
- Analytics Engineer / BI Analyst (1): model core entities + define KPIs.
- Data Engineer (1): set up ingestion/orchestration; enforce tests.
- (Fractional) Data Product Owner: prioritizes requests; defines contracts.
Stage 2: Scale (3–8 people)
- Add Platform Lead/Architect; introduce Governance Lead/Steward.
- Add a second Analytics Engineer and DQ/DRE to cut incidents.
- Start embedded analysts in key domains (e.g., RevOps, Product).
Stage 3: Federate (8–20+)
- Formalize CoE: standards, training, platform SRE, reusable templates.
- Spin up domain pods with domain leads; introduce Data PM.
- Add ML roles only when data quality + observability are solid.
Scaling rule: don’t hire for busywork—automate it. Hire where automation can’t carry the load and ROI is obvious.
Frequently Asked Questions
Because data-driven decisions power customer experience, cost optimization, and product innovation. Without the right team, organizations struggle to turn raw data into trusted insights and actions.
Ask yourself:
- Do we know what drove revenue growth last quarter?
- Are KPIs tracked consistently across teams?
- Can we forecast churn or lifetime value?
If not, start with descriptive and operational analytics before moving to predictive models.
Neither universally. Start centralized for consistency, embed analysts for speed, then adopt a hybrid/CoE to balance both.
Tie metrics to outcomes: time-to-insight, adoption, incident rate, and business KPIs—not dashboard counts. For more insight into measuring data team impact and ROI, check out our guide to the top 10 metrics to measure data team success.
Analytics engineers model data for analysis (tests, docs, metrics); data engineers move/transform data at scale and manage pipelines/platform.
A PM for datasets/metrics: defines contracts, SLAs, owners, and roadmap to maximize reuse and reliability.
After your descriptive and operational layers are stable: reliable pipelines, tests, and a governed metrics layer.