In the ever-evolving world of data management, two architectural paradigms have emerged as front-runners in enabling modern, scalable, and business-aligned data strategies: data mesh and data fabric. While these concepts are often mentioned together, they serve different purposes—and understanding those distinctions is key to building an effective data platform strategy. This article breaks down the core differences, similarities, and benefits of data mesh vs. data fabric—and why choosing the right approach (or a hybrid of both) matters for data leaders, engineers, and organizations looking to maximize value from their data assets.
TL;DR: Quick comparison
| Feature | Data Mesh | Data Fabric |
| Primary Focus | Organizational design, domain ownership | Technology architecture, automation layer |
| Key Enabler | Federated governance, domain-driven ownership | AI/ML-powered metadata and pipeline orchestration |
| Main Benefit | Scales people/processes with decentralized control | Connects data across silos with centralized intelligence |
| Governance Approach | Federated, embedded in domains | Centralized, policy-based, and metadata-driven |
| Tech Stack Dependency | Platform-agnostic (depends on org design) | Typically requires a robust unified tech layer |
| Ideal For | Large orgs with many data domains and ownership needs | Complex data ecosystems needing end-to-end integration |
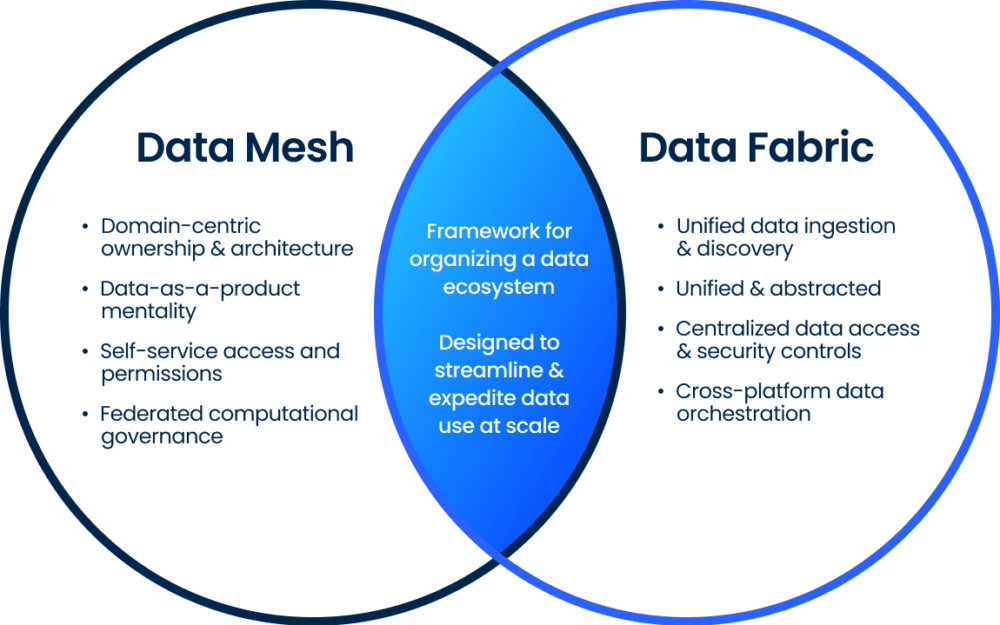
Data mesh vs. data fabric: key differences
Though often mentioned in the same breath, data mesh and data fabric are not interchangeable—they serve different but complementary purposes.
In short:
🔹 Data mesh is the who and how—a framework for decentralizing responsibility.
🔹 Data fabric is the what and where—a foundation for integrating and governing data intelligently.
Together, they lay the groundwork for a modern, scalable, and business-aligned data strategy.
What is data mesh?
Data mesh is a decentralized approach to data architecture that treats data as a product and emphasizes domain-oriented ownership. Rather than centralizing all data responsibilities in a monolithic data team, data mesh distributes accountability to the teams closest to the data.
Data mesh is a shift in mindset and operating model. It decentralizes data ownership and empowers domain teams to treat data as a product, complete with clear accountability and lifecycle management. It’s about how your organization structures data responsibility.
Key principles of data mesh
- Domain ownership: Data is owned by the business units that generate it.
- Data as a product: Each data domain is responsible for producing high-quality, usable data products.
- Self-serve data platform: Teams should be able to publish, access, and transform data autonomously.
- Federated governance: Governance is embedded across domains, not enforced top-down.

Business value
- Encourages scalability by aligning data responsibilities with domain knowledge.
- Increases data trust and accountability.
- Reduces bottlenecks in centralized teams.
What is data fabric?
Data fabric is a technology-centric approach that uses metadata-driven automation and AI to create a unified data environment. It’s about intelligent data integration—stitching together siloed data sources in real time and providing a consistent layer of access, governance, and observability.
Data fabric is the technical backbone—a set of intelligent, automated services that unify and manage data across sources, platforms, and environments. It provides the infrastructure and connective layer needed to ensure consistent access, governance, and quality at scale.

Key components of data fabric
- Metadata management: Automates data discovery, classification, and lineage.
- Data integration tools: Seamless connections across cloud and on-prem environments.
- AI and automation: Powers data quality, cataloging, and pipeline optimization.
- Centralized governance: Policies and access control applied holistically.
Business value
- Breaks down data silos without requiring organizational restructuring.
- Accelerates data discovery and delivery through automation.
- Improves data quality and governance at scale.
When to use data mesh vs. data fabric
| Use Case | Data Mesh | Data Fabric |
| You have many domain-specific teams with distinct data needs | ✅ | ✅ |
| You want to reduce reliance on centralized data teams | ✅ | ❌ |
| You need real-time integration across diverse data sources | ❌ | ✅ |
| You’re aiming to scale data governance across global teams | ✅ | ✅ |
| You’re focused on automating data operations and metadata management | ❌ | ✅ |
The Coalesce point of view: Why not both?
At Coalesce, we see value in combining the strengths of both approaches. In practice, organizations benefit most when:
- Data mesh principles guide organizational structure, giving teams autonomy to own, build, and serve data products.
- Data fabric technologies power the platform layer, enabling metadata-driven transformation, governance, and collaboration.
The Coalesce platform bridges both worlds:
- Visual, metadata-aware data transformations that support domain-driven development.
- Governance built into every transformation, not bolted on.
- Automation and orchestration that scale with your architecture—whether it’s centralized, decentralized, or hybrid.
Combining data mesh and data fabric to unlock more business value
Innovative organizations are moving beyond traditional data architectures by blending data mesh and data fabric into a unified strategy. While each concept offers distinct advantages, their real power lies in complementing one another—balancing autonomy with consistency, speed with security, and innovation with control.
Data mesh decentralizes data ownership, shifting data responsibility to domain teams closest to the business logic and context. This approach encourages accountability, accelerates data delivery, and enables faster iteration. However, without the proper guardrails, it can lead to fragmented governance, inconsistent standards, and duplicated efforts.
This is where data fabric plays a critical role. Acting as the connective tissue of your data ecosystem, the data fabric weaves together diverse data sources using metadata-driven intelligence, automation, and centralized governance. It ensures interoperability, discoverability, and compliance across your entire organization—no matter where the data resides or who owns it.
Together, a data mesh + data fabric strategy delivers measurable business value:
🔹 Faster, more relevant insights: Domain teams deliver high-quality data products faster, aligned to business needs—without waiting on centralized bottlenecks.
🔹 Improved data governance at scale: The fabric enforces enterprise-wide policies for data quality, lineage, access, and security without stifling local innovation.
🔹 Greater agility and resilience: As market demands shift, teams can pivot quickly without reinventing the wheel—thanks to reusable components and shared infrastructure.
🔹 Enhanced collaboration and reuse: Teams gain visibility into each other’s data assets, promoting reuse and reducing redundant work across departments.
🔹 Optimized data investments: Aligning people, processes, and technology around centralized oversight and decentralized execution ensures more intelligent, sustainable data management.
Organizations can finally escape the false choice between agility and control by integrating the data mesh’s decentralized ownership with the data fabric’s centralized intelligence—the result: a flexible, federated, and future-proof data strategy that maximizes both innovation and trust.
Final thoughts
While data mesh and data fabric offer different paths to solving data challenges, they’re not mutually exclusive. Think of them as complementary:
- Data mesh reshapes how you organize and think about data ownership.
- Data fabric empowers you to automate, govern, and unify data flows.
The most successful data-driven organizations combine both—adopting a federated mindset while building on a modern, AI-assisted data platform.
Ready to modernize your data architecture? Learn how Coalesce helps data teams decentralize data ownership and move faster, with confidence.
Go from data mess to data mesh with Coalesce
Decentralize data ownership across your organization by giving every data expert the ability to create and consume data products.